系统设计面试-总览
Contents
步骤1: 明确要求
提问来确定问题的范围 设计问题 没有唯一的正确答案,需要在一开始就要定义问题的目标 因为只有35-40分钟的时间来设计, 应该关注系统的核心部分
开发一个类似Twitte的服务
- 用户可以发送twitter并且关注其他人?
- 是否需要设计用户的时间线
- twitter是否包含图片和视频
- 需要只关注后端还是关注前后端
- 是否支持搜索twitter
- 是否需要展示热度主题
- 是否需要推送通知
步骤2: 接口定义
定义系统的APIs
postTweet(user_id, tweet_data, tweet_location, user_location, timestamp, …)
generateTimeline(user_id, current_time, user_location, …)
markTweetFavorite(user_id, tweet_id, timestamp, …)
步骤3: 系统估计
预估系统的规模,方便后续关注服务扩容,分区,负载均衡,缓存
- 系统的规模 ( 新twitter的数量,tweet被查看的数量,每秒生成多少时间线)
- 需要多大的存储空间?如果支持用户发送图片和视频,这个数量是否变化?
- 网络带宽?这是管理事务和服务负载均衡的关键
步骤4: 定义数据模型
定义数据模型来明确系统的组件的交互,来帮助数据的分区和管理 定义系统的实体以及实体之间如何交互以及数据管理,比如存储,流转,加密
User:* UserID, Name, Email, DoB, CreationData, LastLogin, etc.
Tweet:* TweetID, Content, TweetLocation, NumberOfLikes, TimeStamp, etc.
UserFollowos:* UserdID1, UserID2
FavoriteTweets:* UserID, TweetID, TimeStamp
数据库类型如何选择?SQL还是NOSQL? 图片和视频用什么来存储?
步骤5:顶层设计
画图来展示系统的核心组件。定义足够的组件从前后端分析,来解决实际的问题,
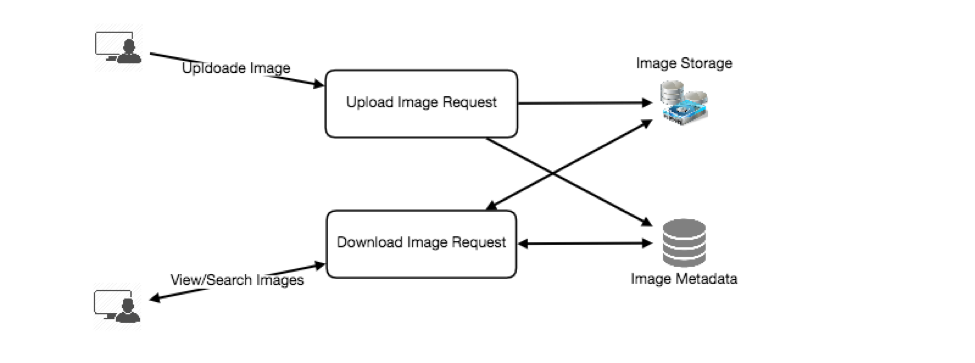
Twitter的的话,需要分布式的负载大量的读写请求 假设我们有大量的读事务(写事务),我们需要根据使用场景来分离这些服务 我们需要高效的数据库来存储大量的Twitter来提供大量的读请求 我们也需要分布式的文件存储,来存储图片和视频
步骤6:细节设计
深入2-3个组件,设计面试通常希望你深入解释一些组件 你需要提供不同的方案,优点/缺点,你选择的理由 方案没有完美的答案,重要是取舍和权衡
- 由于我们存储大量数据,如何进行数据分区?存储某一用户的所有数据在一个数据库?这样会造成什么问题?
- 如何处理热度人物,比如有很多粉丝的用户
- 时间线包含了最近的Twitter, 如何设计数据结构来存储最新的twitter?
- 哪一个层需要引入缓存,以及需要缓存多少数据来进行加速?
- 哪些组件需要更好的负载均衡
步骤7:验证并且解决瓶颈
尽可能的讨论可能的系统瓶颈并且不同措施来减轻
- 系统是否存在单点问题?如何避免单点?
- 数据是否有复制/备份,防止部分数据丢失,导致故障
- 类似,服务是否多机部署,防止一部分失败后,整体服务挂掉
- 如何监控服务的性能?当核心服务失败或者性能下降的时候得到报警?
Author tmackan
LastMod 2020-12-28